
昨年ぐらいからお客さんのところでも「機械学習やってみたいね」みたいな話が出てきていて、
そろそろ私も機械学習(Machine Learning)とはなんぞや、というレベルからでもはじめないとだなー、とは思っていた。
で、Googleが出しているフリーの深層学習(deep-learning)のライブラリであるTensorflowの勉強会が、 たまたま地元で7月中旬、8月末と二回ほどあったので参加してきた。
2013年ごろから、異常にコンピュータの画像認識能力が上がってきたのは、tensorflowなどの深層学習系AIの成果である。
深層学習とはなんぞや、というと簡単言うと、
- まず、生物の神経回路を模したニューラルネットワークをつくっておく。
- 初期状態では何も勉強していないので何も知らない状態である
- このニューラルネットワークに「問題」と「答え」を、とにかく大量に与える。
- この問題を解いて不正解だった場合、ニューラルネットワークのパラメータを適当に変える
- そうすると、そのうち正解の確率が高くなる
- 問題を解けば解くほど頭がよくなる
みたいなので、人間があらかじめ「この場合はこう判断しなさい」というルールを作る必要がなく、
とくにかく問題を大量に与えるのが重要になってくるらしい。
というか、むしろ、機械がどうしてそのような判断をするようになったのかは、人間にはわからない。
機械の頭の中で大量の経験が蓄積されて、この場合はこうだな、という神経回路が勝手にできているので、
「このA大学のB君だが、内定辞退率が70%超えているのはどうゆうことだね?」「いや、わかりません、過去30万人の就活生から機械が判断したことなので」みたいな感じになるわけである。
昔はデータを集めることが大変だったが、現在ではインターネットの発達や携帯電話やその他の小型デバイスの普及により、データが大量に集められるようになってきた。
それで、ようやく深層学習させられる環境が整ってきた、という感じのようである。
Tensorflowで手書き数字を認識させてみる
で、まあ、私も機械学習のHello Worldに相当するという「MNIST」というデータセットを使った手書き文字の認識をさせてみたわけですよ。
こんな感じの手書き文字(28×28ドット)の画像が6万個あって、これを学習させる。
import matplotlib.pyplot as plt
%matplotlib inline
for i in range(10):
plt.subplot(5, 5, i + 1)
img = train_images_src[i]
plt.ylabel(f"{train_labels_src[i]}")
plt.imshow(img, cmap = 'binary')
plt.show()
print(len(train_images_src))
print(train_images_src[0].shape)

で、モデルは講習会で聞いてきたのを適当にマネしてみる
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) # 3x3の畳み込みカーネル(フィルタ) を32個、入力層は(28 x 28 x 1チャンネル)
model.add(layers.MaxPooling2D((2, 2))) # 2x2のMax Pooling
model.add(layers.Conv2D(64, (3, 3), activation='relu')) # 3x3の畳み込みカーネル(フィルタ) を64個, maxpoolingで半分に減るのでフィルタを倍にして要素数を維持する
model.add(layers.MaxPooling2D((2, 2))) # 2x2のMax Pooling
model.add(layers.Flatten()) # 平滑化 二次元をdenseに渡すために一次元にする。
model.add(layers.Dense(128, activation='relu')) # ノード数が128個の全結合層
model.add(layers.Dense(10, activation='softmax')) # 出力層
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1600) 0
_________________________________________________________________
dense (Dense) (None, 128) 204928
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 225,034
Trainable params: 225,034
Non-trainable params: 0
_________________________________________________________________
それを、うちのマシンで学習させると、だいたい以下のような感じの時間がかかる。
model.compile(
loss = 'categorical_crossentropy', # 損失関数は「categorical_crossentropy」
optimizer = 'rmsprop', # オプティマイザは「rmsprop」
metrics = ['accuracy'] # 指標は「accuracy」(正答率)
)
# epochs: 全データを繰り返し学習する回数
# batch_size: 1度に投入する入力データ数
history = model.fit(train_images, train_labels, epochs=5, batch_size=128)
Epoch 1/5
60000/60000 [==============================] - 31s 520us/sample - loss: 0.2047 - acc: 0.9361
Epoch 2/5
60000/60000 [==============================] - 31s 523us/sample - loss: 0.0537 - acc: 0.9834
Epoch 3/5
60000/60000 [==============================] - 31s 510us/sample - loss: 0.0348 - acc: 0.9890
Epoch 4/5
60000/60000 [==============================] - 30s 508us/sample - loss: 0.0261 - acc: 0.9916
Epoch 5/5
60000/60000 [==============================] - 30s 505us/sample - loss: 0.0193 - acc: 0.9935
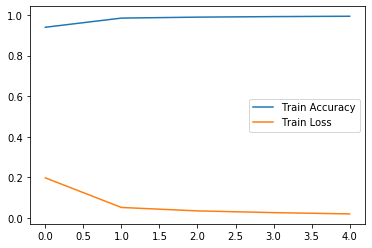
で、学習曲線は、こんな感じになる。
# 学習の推移をグラフ化
import matplotlib.pyplot as plt
%matplotlib inline
acc = history.history['acc'] # 学習データの正答率
loss = history.history['loss'] # 学習データの損失
epochs = range(len(acc))
plt.plot(epochs, acc, label='Train Accuracy')
plt.plot(epochs, loss, label='Train Loss')
plt.legend()
plt.show()
で、これを学習データとは別の、1万個のテスト用の手書き画像で推論させてみると
(test_loss, test_acc) = model.evaluate(test_images, test_labels)
print('test_acc: ', test_acc)
10000/10000 [==============================] - 2s 179us/sample - loss: 0.0278 - acc: 0.9906
test_acc: 0.9906
軽く学習させた程度だけど、99%の正解率なので、
まあ悪くはないのではー?と思って、その1%の間違いは何か見てみるわけですよ。
# 推論して、間違いと判定された画像をいくつか表示してみる
import numpy as np
err_count = 0
for i in range(len(test_images)):
img_data = test_images[i]
# 画像を1枚だけのバッチのメンバーにする
img_data = (np.expand_dims(img_data,0))
y_prob = model.predict(img_data) # 推論する
y_pred = np.argmax(y_prob, axis=1) # one host配列からインデックスに戻す
if y_pred[0] != test_labels_src[i]:
img = test_images_src[i]
plt.ylabel(f"{test_labels_src[i]}")
plt.imshow(img, cmap = 'binary')
plt.show()
err_count += 1
print('No,', err_count, ' 推論: ', y_pred[0], ', 正解:', test_labels_src[i])
if err_count > 20:
break
0を5と間違えていたり、(…いや、5にはみえんだろ?)
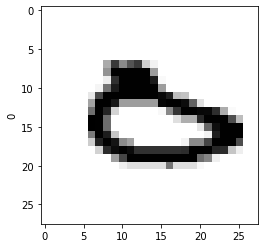
1を2と間違えていたり、
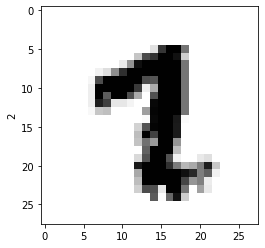
2を7と間違えていたり、 (…いや、7にはみえんだろ?)
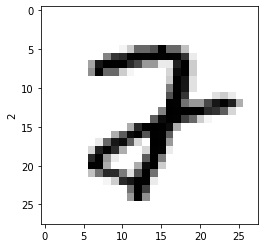
3を5と間違えていたり、 (…いや、どうみても3だろ?)
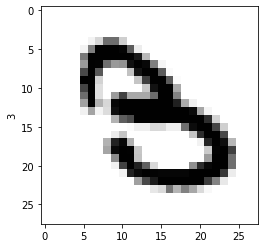
これは…、どうして間違えた?
いや、これは人間なら絶対に間違えないよね…?
99%あってるから、1%が、よほどわかりにくい数字かと思ったのに、そうでもない。
そうか、これが機械学習か…。わからん。
(たぶん、人は書き順という時系列を意識して字を識別しているのだろうけど、画像の類似性だけで判断するとこうなるようだ。)
ちなみに、講習会では、チューリップとダンデライオンと何かの花の4種類の判定をする演習があったのだが、私が作ったモデルは、良くて7~8割ぐらいで、チューリップとたんぽぽを余裕で間違えているので、いや…これはヤバいね、どうやって実用化するの?という感じでした。(上手な人は9割ぐらいいってたみたいだが)
たかだか16時間やったぐらいでは全然だめで、モデルの組み方とか、いろいろ試さないと簡単にはゆかなそう。
TensorflowをGPUで動かしてみる
さて、ここからが本題で、以前から少し興味があったGPUを使った機械学習をやってみた。
買ったのは、このエントリーモデルの低価格グラボ GeForce GTX 1650 、16000円ぐらいのもの。
昔からパソコンでアクションゲームをすることが(ほとんど)なくて、現在使っているマシンのグラボは、6年ぐらい前のAMD FirePro V3900であった。(CPUも、Xeon E3-1270 V2 3.5GHz)
このマシンでは、三次元計算をさせることが全くて、Steamで遊んでいるゲームもシューティング数本ぐらい[1]だけなので、まったく全然問題なかったのだが、
アイドル部のなとなと🌾のライトボーガンや、ゲーマーズ出身のひまちゃん 🌻 のガンランスとか、楽しそうにモンハンワールドを遊んでいるのを見て、PS4持ってないけど、やってみたいなー、とかちょっと思っていたところ、お盆休みのころ、Steamでモンハンが割引販売(2995円)されていたので、スペックが全然足りていないことはわかっていたけれど買ってみたのである。(ちなみにポータブル2Gのころから弓を好んで使っていた。たまにガンランス。)
このマシンで、正直、どの程度動くのかな、というのを見てから、必要なグラボの性能を逆算しようという魂胆だったわけだが、AMD FirePro V3900は、すごくトロくてゲームにならないけれど、一応、動く、ということが分かった。
このことから、モンハンをプレイするのには最新の高額なグラボでなくても、少し型落ちした古いアーキテクチャのグラボでも十分いけそうな感じがして、ここからネットの情報をあさってみると、モンハンが遊べそうな最低価格のグラボとしては「GeForce GTX 1650」ぐらいならば、まあまあ遊べないことはなさそうだ、という情報があったので、これを選択した。
一万円台で買えるエントリモデルのグラボとしては他にも選択肢はあって、むしろ、GTX 1650は、性能に対する価格としては、コスパ的にはよろしくないという批評もあったが、ここは、あえて、GeForceにした。
ゲームをやってみたい、というのは動機ではあるけれど、そもそも、このマシンはゲーム機ではない。
機械学習みたいな行列計算を多用する場合、CPUではなくGPUのほうが向いていて、GPUを並列計算器として使う場合の汎用ライブラリとしてNVIDIAが開発しているCUDAというものが、結構デファクト的に有名なのである。
このCUDAを使って並列演算させるためには、NVIDIAのグラボが必要になるので、選択肢としては、その中でもっとも廉価なGeForceになったわけである。
で、実際にTensorflowをGPUで動かしてみた。
Windows10(64bit)のHyper-Vが有効なマシンなので、CUDAを使うのにHyper-Vが邪魔になるのか心配だったが杞憂だった。
以下のものをインストールした。
- GeForce_Experience_v3.20.0.118.exe
- cuda_10.0.130_411.31_win10.exe
- cudnn-10.0-windows10-x64-v7.6.3.30.zip
ちなみに、Pythonは3.7.4を使った。(デフォルトが32ビット版のダウンロードになるので、64ビット版を明示的に選択する必要あり。tensorflowは64ビットでのみ動作する。)
※ 2019/9/8時点で、CUDAは10.1、cudnnも10.1が最新だが、これがtensorflow-gpu==1.14.0だと、バージョン不一致で動かない。tensorflow1.14だと、CUDA10.0系のDLLを見ているようである。(おそらくTensorflow2-rc0でも同じだと思う。)
(最新版で動くかなー、と思って10.1を入れたら、tensorflowから呼び出すときのdllの名前が違ってうごかなかった。dll名をだますために、10.1のdllをScriptディレクトリ上にsymlinkする、というネットにあった荒技も試してみたが、これにより簡単なものは動いたが、今回のコードでは結局、不可解なエラーになって動かなかった。結論としては、10.0でないと動かないということだろう。)
まず、GeForce Experienceを入れることにより、グラボのドライバが最新であるかなどのチェック等々をしてくれる。
このあとで、CUDA10.0をインストールするが、CUDAはSDKみたいなもので、全部で2GB以上のサイズである。
CUDAをインストールするとVisual Studioのサンプルもあるので、これをビルドすると、いろいろ試せる。
$ deviceQuery.exe
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1650"
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 4096 MBytes (4294967296 bytes)
(14) Multiprocessors, ( 64) CUDA Cores/MP: 896 CUDA Cores
GPU Max Clock rate: 1680 MHz (1.68 GHz)
Memory Clock rate: 4001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.1, NumDevs = 1
Result = PASS
(最初、CUDA10.1を入れてしまったので、そのときの結果だが)
ということで、CUDAが動いてGTX1650に無事アクセスできているようなので、とりあえず大丈夫そう。
つぎに、cudnnという深層学習用のニューラルネットワークのライブラリを入手する。
https://developer.nvidia.com/cudnn
これがnVidiaにユーザー登録するとダウンロードできるようになる。
これはインストーラとかないので、適当な場所に展開してdllにパスを通す。
最後に
pip install tensorflow-gpu
みたいにしてgpu対応版のtensorflowを入れれば、GPUを使ってくれる。
実際に使って、先ほどと同じものを動かしてみると以下のような感じになった。
2019-09-07 22:58:25.092489: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library nvcuda.dll
2019-09-07 22:58:25.236859: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties:
name: GeForce GTX 1650 major: 7 minor: 5 memoryClockRate(GHz): 1.68
pciBusID: 0000:01:00.0
2019-09-07 22:58:25.248665: I tensorflow/stream_executor/platform/default/dlopen_checker_stub.cc:25] GPU libraries are statically linked, skip dlopen check.
2019-09-07 22:58:25.258277: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0
2019-09-07 22:58:25.920255: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-09-07 22:58:25.928725: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1187] 0
2019-09-07 22:58:25.933623: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1200] 0: N
2019-09-07 22:58:25.939667: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 2931 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1650, pci bus id: 0000:01:00.0, compute capability: 7.5)
で、一応、動いているようだ。
計算時間は、以下のようになった。
Epoch 1/5
60000/60000 [==============================] - 27s 456us/sample - loss: 0.1973 - acc: 0.9396
Epoch 2/5
60000/60000 [==============================] - 20s 338us/sample - loss: 0.0513 - acc: 0.9847 - loss: 0.0
Epoch 3/5
60000/60000 [==============================] - 20s 336us/sample - loss: 0.0343 - acc: 0.9895
Epoch 4/5
60000/60000 [==============================] - 20s 336us/sample - loss: 0.0259 - acc: 0.9921
Epoch 5/5
60000/60000 [==============================] - 20s 336us/sample - loss: 0.0194 - acc: 0.9939
30秒かかっていたのが20秒だから、結構、効果がある感じ。
講習会ではGoogleのクラウド上で使うフリーのJupyter環境であるGoogle Colaboratoryも使っていて、これはGPUによる計算のオプションを選択できる。
が、講習会の課題では、CPUではなくGPUで計算してもぜんぜん速くならなかった。
講師の人も、おそらく、並列計算させるよりも前の段階の画像のサイズ変更などの処理に時間の大半が食われていたためではないか、と推測されていた。
ネットの散見する記事では、人によっては、GTX1050tiを使ったらCPUと比較して計算時間が1/7に短縮された、みたいなケースもあるようなので、低価格なGeForceであっても、使い方によっては絶大な効果を発揮するのかもしれない。
とりあえず、今日の実験は、ここまで。
☆ Postscript: モンハンワールドのこと ☆
モンハンはインストールしてから、現在までプレイ時間は5時間ぐらいかな。探索に行って操作練習したりして、クエストは3個ぐらいしか進めていないけど、一応、まともにゲームできるようになったような気がする。
キーボードでのゲーム操作に慣れていないのでXBox360のコントローラも買ってみた。弓とかライトボーガンみたいなものならマウスで照準をあわせたほうがAIMが良いという話もあるようだが、そもそも自機の移動やカメラ操作でさえ苦労しているので、とりあえずゲームパッドでやってみようと思っている。ひさしぶりに長く遊べそうな気がする。
アイドル部のめめめさん🐏が、ちょうど今日からモンハンワールドPC版を始めたとのことなので、彼女の配信と、彼女のファンである毛玉さんたちのコメントをみて、いろいろ勉強させてもらおうと思う。
[1]昔ゲームセンターで遊んだトラブルウィッチーズと斑鳩だけ記念品的な感じで入れている
